"The Car Wash Test" on 4 Frontier LLMs
The car wash is 100m away from my house. Should I walk or drive? LLMs tackle this test in surprisingly different ways
"The car wash is 100m away from my house. Should I walk or drive?"
How do LLMs deal with contextual ambiguity in low-stakes situations?
This test went viral in March 2026, because we humans find the answer to be genuinely obvious: if you're going to wash your car, you're going to need your car. However, the question does not contain any information on intent. It is never explicitly stated that you want to wash your car. Can an LLM extract intent that seems obvious to most humans? This is the semantic trap we decided to test.
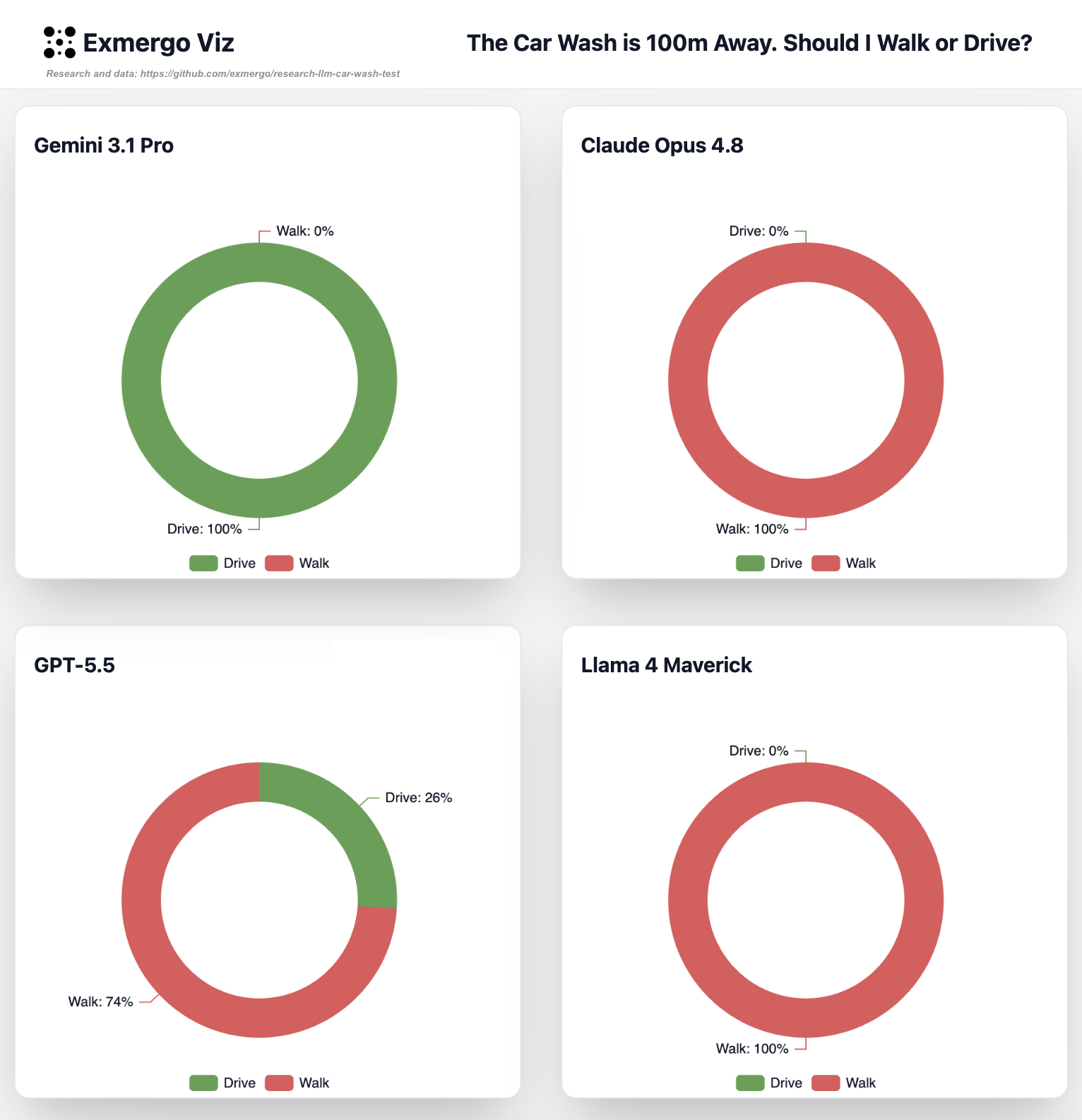
We asked four frontier LLMs this exact question 100 times each (N = 400) and recorded which way each one committed.
This is open research by Exmergo. We build AI agents for data analytics. The full interactive visualization is in Exmergo Viz: view the dashboard →.
Results
Three of the four models fail the trap most or all of the time. The only model that reliably passes is also the one that reasons the hardest.
| Model | Decision = Drive (Pass) | Decision = Walk (Fail) | Pass rate | Reasoned | Mean reasoning tokens |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | 100 / 100 | 0 | 100% | 100% | 450 |
| GPT-5.5 | 26 / 100 | 74 | 26% | 100% | 105 |
| Claude Opus 4.8 | 0 / 100 | 100 | 0% | 0% | 0 |
| Llama 4 Maverick | 0 / 100 | 100 | 0% | 0% | 0 |
Source: data/processed/model_aggregate.csv.
All 400 calls returned a valid, parseable decision — 0 format failures, 0
infrastructure failures.
What stands out
- Gemini 3.1 Pro got it right every single time (100/100) — and it spent the most effort thinking (~450 reasoning tokens per answer). When it reasons, it consistently surfaces the functional point: you must bring the car.
- GPT-5.5 reasoned on every response (~105 tokens each) and still failed 74% of the time. This is the most interesting result: explicit reasoning was necessary but not sufficient. GPT often deliberated and still defaulted to the semantically primed "Walk."
- Claude Opus 4.8 failed all 100. With adaptive thinking, the default mode users get in the Claude app, Claude judged the question trivial and spent zero reasoning tokens on every attempt. The model allowed to decide whether to think decided not to, and walked straight into the trap. (Its prose often did note "if you're washing the car you'd need to drive", but it still decided to Walk.)
- Llama 4 Maverick failed all 100 — expected for a non-reasoning model answering on surface features.
Reasoning effort tracks success (Gemini > GPT > the rest), but even a frontier reasoning model that thinks every time can still lose to a one-line semantic trap.
Methodology
Full design rationale is in
docs/Car Wash Logic Trap SDD.md.
The essentials:
The prompt
A single, fixed user message, sent identically for all 400 calls:
The car wash is 100m away from my house. Should I walk or drive.
Lead with your decision - either "Walk" or "Drive" and then provide your reasoning
The "lead with your decision" instruction turns a free-text answer into a measurable binary while still letting the model explain itself. Only the leading token is scored (see Classification below).
The models & how they were reached
All four models are called through OpenRouter's
OpenAI-compatible endpoint, so one API key reproduces the entire benchmark.
OpenRouter routes the proprietary models to their first-party providers
(confirmed in the Provider column: Anthropic, OpenAI, Google), and the
open-weight model to a pinned provider.
| Model | OpenRouter slug | Provider | Reasoning treatment |
|---|---|---|---|
| Claude Opus 4.8 | anthropic/claude-opus-4.8 | Anthropic | reasoning: {enabled: true} — adaptive (model chooses whether to think) |
| GPT-5.5 | openai/gpt-5.5 | OpenAI | reasoning: {effort: high} (forced) |
| Gemini 3.1 Pro | google/gemini-3.1-pro-preview | reasoning: {effort: high} (forced) | |
| Llama 4 Maverick | meta-llama/llama-4-maverick | DeepInfra (fp8, pinned) | effort: high requested; non-reasoning model ignores it |
A note on the reasoning asymmetry: this is deliberate and is part of the
finding. Claude 4.6+ ignores the effort parameter; it only
engages extended thinking when given an explicit token budget. We chose to use
its native adaptive mode rather than force a budget, precisely to observe
what the model does when left to decide for itself whether the question is
worth thinking about. It decided it wasn't. We requested high reasoning effort
from every model in its native idiom; we did not force equal token spend.
Parameters
- Temperature: not set (each model runs at its provider default). With
extended reasoning, sampling temperature is ignored or forbidden on most
reasoning APIs (Claude with thinking requires
temperature = 1.0), so a uniform value would be both meaningless and liable to break the Claude run. Run-to-run variation comes from inherent sampling/reasoning-trajectory stochasticity across the 100 trials. - Max output tokens: 1000 — every model's thinking + answer fit comfortably
under it (observed completion totals ≤ ~560). Each row records
finish_reasonto flag any truncation. - Sample size: N = 100 per model, 400 total.
Classification (strict, deterministic)
The model was told to lead with its decision, so classification looks only at
the leading token of the response (after tolerating markdown/quote/whitespace
noise like **Drive**):
| Lead token | Outcome |
|---|---|
Drive | Pass — applied functional logic (the car must be present) |
Walk | Fail — fell for the "100m → walk" semantic trap |
| neither | Format_Failure — ignored the instruction |
Hedging or conditional reasoning later in the answer does not change the outcome. The whole question is which way the model commits when asked for a binary. (See the SDD's Limitations for why we deliberately avoided an LLM-as-judge: it would introduce non-determinism and the circularity of using an LLM to grade an LLM-skepticism benchmark.)
Limitations
- Single prompt. LLMs are sensitive to phrasing; "1 block" instead of "100m" could shift results. We fix and publish the exact prompt.
- N = 100 gives roughly a ±10-point 95% confidence interval on each percentage. The two 0/100 and one 100/100 results are unambiguous regardless.
- The open-weight model is benchmarked quantized (fp8). Frontier-scale open weights aren't served unquantized on OpenRouter, so Maverick's result can't be cleanly separated from quantization effects.
- "Drive is correct" assumes the obvious intent (you're taking your car to be washed). A model reading the question as "I'm visiting the car-wash location for some other reason" could justify "Walk." However, that is not the natural reading, and it is the trap.
- Not an exhaustive reasoning test. Failing this physical-logic probe says nothing about a model's coding, math, or summarization ability.
The pipeline
collect → clean → transform. Each stage reads the previous stage's committed
CSV, so any stage can be re-run independently.
| Stage | Module | Output |
|---|---|---|
| Collect | logic_trap.collect | data/raw/model_responses.csv (+ run_metadata.json, collection.log) |
| Clean | logic_trap.clean | data/processed/model_responses_clean.csv (+ rejected_rows.csv) |
| Transform | logic_trap.transform | data/processed/model_aggregate.csv |
Raw, cleaned, and aggregate datasets are all committed to this repo, so the analysis is fully reproducible with no API spend.
Setup
This project uses uv for everything.
uv sync
There are two ways to run it. Path 1 is free.
Path 1 — Reproduce the analysis (free, no API key)
The raw dataset is committed, so you can regenerate the cleaned data and the aggregate table — and verify every number in the Results table — without spending a cent:
uv run python -m logic_trap.pipeline # runs clean -> transform
Or run the stages individually:
uv run python -m logic_trap.clean
uv run python -m logic_trap.transform
Path 2 — Collect fresh data (requires an OpenRouter API key, costs money)
This re-queries all four models 100 times each. Only do this if you want to collect a new dataset.
cp .env.example .env # then edit .env and add your OPENROUTER_API_KEY
uv run python -m logic_trap.collect
# then run the pipeline above on your fresh data
Cost & runtime: 400 calls to four premium reasoning models. Reasoning tokens
dominate the cost — budget on the order of a few US dollars and a few minutes at
the default concurrency. OpenRouter reserves credits up front for the maximum
possible output, so your key needs enough balance to cover
max_output_tokens × the per-model output price. The collector refuses to
overwrite an existing raw CSV — delete data/raw/model_responses.csv first to
re-collect.
All experiment parameters (models, prompt, reasoning config, sample size,
concurrency) live in src/logic_trap/config.py and
can be overridden via environment variables — see
.env.example.
Visualization
The 100% stacked bar chart is built in Exmergo Viz (our AI dashboard agent)
directly from data/processed/model_aggregate.csv. The chart spec is committed
at docs/viz/chart_spec.md so it can be rebuilt in any
tool. Interactive dashboard: view the dashboard →.
Development
uv run ruff check .
uv run ruff format .
uv run mypy src
uv run pytest
See CONTRIBUTING.md.
License
MIT — see LICENSE. Dataset and code free to reuse with attribution.
About Exmergo
Exmergo builds AI agents for data analytics. This benchmark is part of our open research exploring the strengths and limitations of frontier LLMs. If you found it useful, you can find more of our studies on our open research page. The conversation usually happens on our socials, where you can come argue with us about whether "Drive" is really the only right answer.